Timeline: Multiple releases across mid 2025 to early 2026
The setup
I've led product and design at FullyRamped since before the first MVP shipped. All of what's in the product today I scoped, designed, and took through to launch with the team. This case study is one slice of that: how we built the assignments product, and how we got there in three small steps instead of one big one.
FullyRamped lets sales & enablement teams build interactive AI simulations of their real customer calls so sales reps can practice hyper-realistic scenarios on demand. Early on, the core practice loop worked. Reps could open the library, pick a simulation, and run a call. Good for self-directed reps. Useless for the part of the job enablement actually gets paid for, which is making sure the *right* people practice the *right* things.
The customer ask was simple in shape and messy in detail. Managers wanted a way to say "here are the sims I need you to run." Reps wanted to know what was actually expected of them versus what was just sitting in the library.
I didn't want to build an learning management system (LMS). LMSs are bloated, and most of the weight in them is there because someone demanded it once and it never got removed. The question I cared about: what is the smallest surface that lets a manager guide a rep, and how do we know when it needs to get bigger?
So we ran it as a series of experiments. Three versions, each one cheaper than the next would have been if we'd tried to skip ahead.
V0: shared with me
Hypothesis: Managers mostly just need a way to surface *which* sims a rep should care about. That's it. Not tracking, not due dates, not scoring. Just visibility.
My "PRD" (bullet points and a loom video)
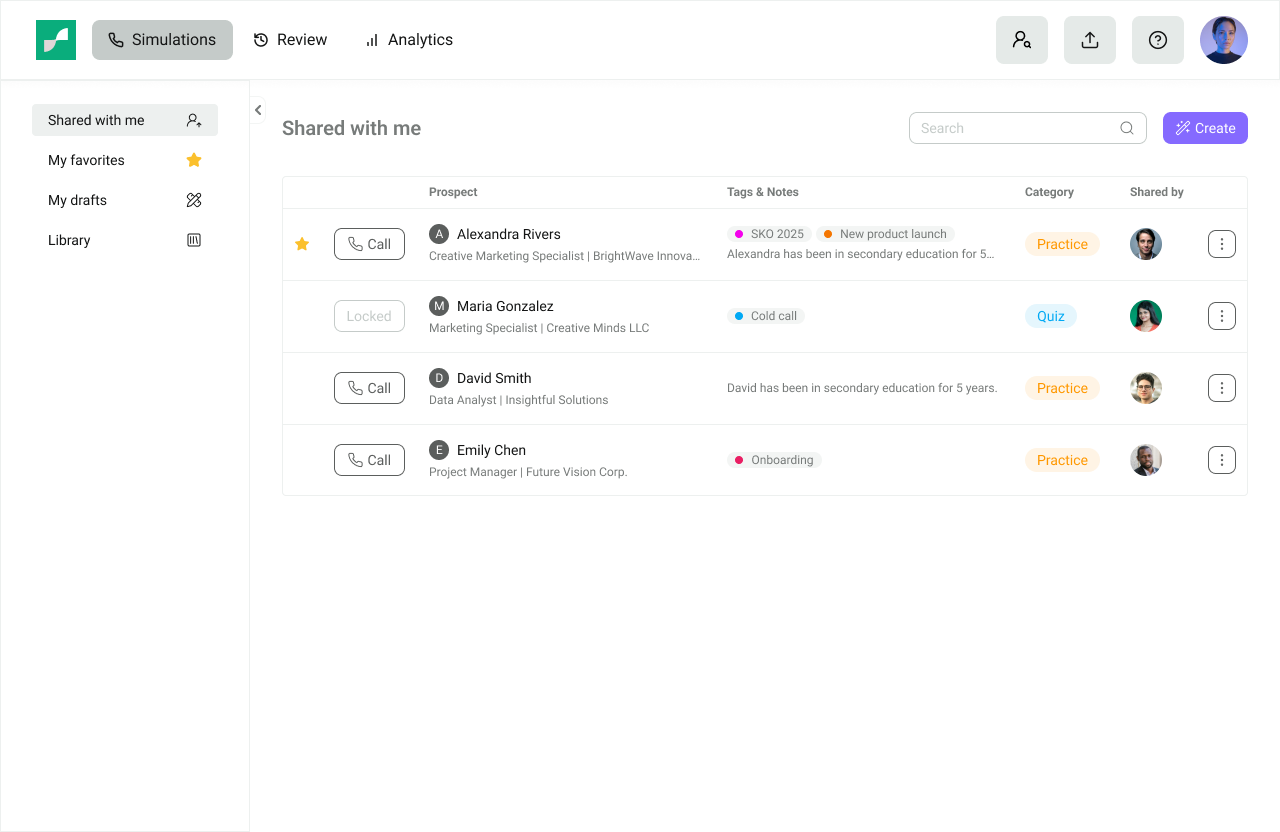
What we shipped: A "shared with me" page. Managers could mark any sim as shared to a specific rep or team, and that rep would see it at the top of their practice view. Think Google Drive's shared folder. Nothing fancy.
A couple of hours of engineering time. No PRD. A handful of bullets in a Linear ticket, which is the right level of detail when you're testing a one-line hypothesis.
The simplest version we shipped of the "Shared with me" page. A list of simulations.
What we learned: It worked, but not the way I expected. Managers did share sims, and reps did use the shared page. But the moment a manager shared more than three or four sims, it stopped feeling like guidance and started feeling like clutter. There was no signal for "you need to do this" versus "you might find this useful." Customers kept asking variants of the same question: "how do I know if my rep actually did it?"
Shared with me solved discovery. It didn't solve accountability, and accountability turned out to be the actual job.
V1: assignments, the basic version
Hypothesis: Managers need a container that says "do these sims, in this grouping, and I'll know when you're done." Not a full LMS. Just the MVP of homework.
Before building, I wanted to know what "basic" actually meant in the LMS world so we didn't accidentally reinvent something badly. I did two things in parallel:
- Customer interviews. I joined QBRs with customers we already knew wanted this feature and probed about how they "assigned" training today. What tools were they using? What was the last thing they assigned? Where did it fall apart between "I assigned it" and "I checked if it was done"? I watched them use their existing LMS tools live and clocked what they reached for and what they ignored
- LMS benchmarking. I went through the assignment flows of a handful of LMS platforms to map the feature surface. The goal wasn't to copy. It was to figure out which features were load-bearing and which were there because some enterprise buyer in 2014 asked for them.
The takeaway reframed the hypothesis. Managers didn't want to build training. They wanted to aim it. The actual job was less like a course builder and more like a playlist.
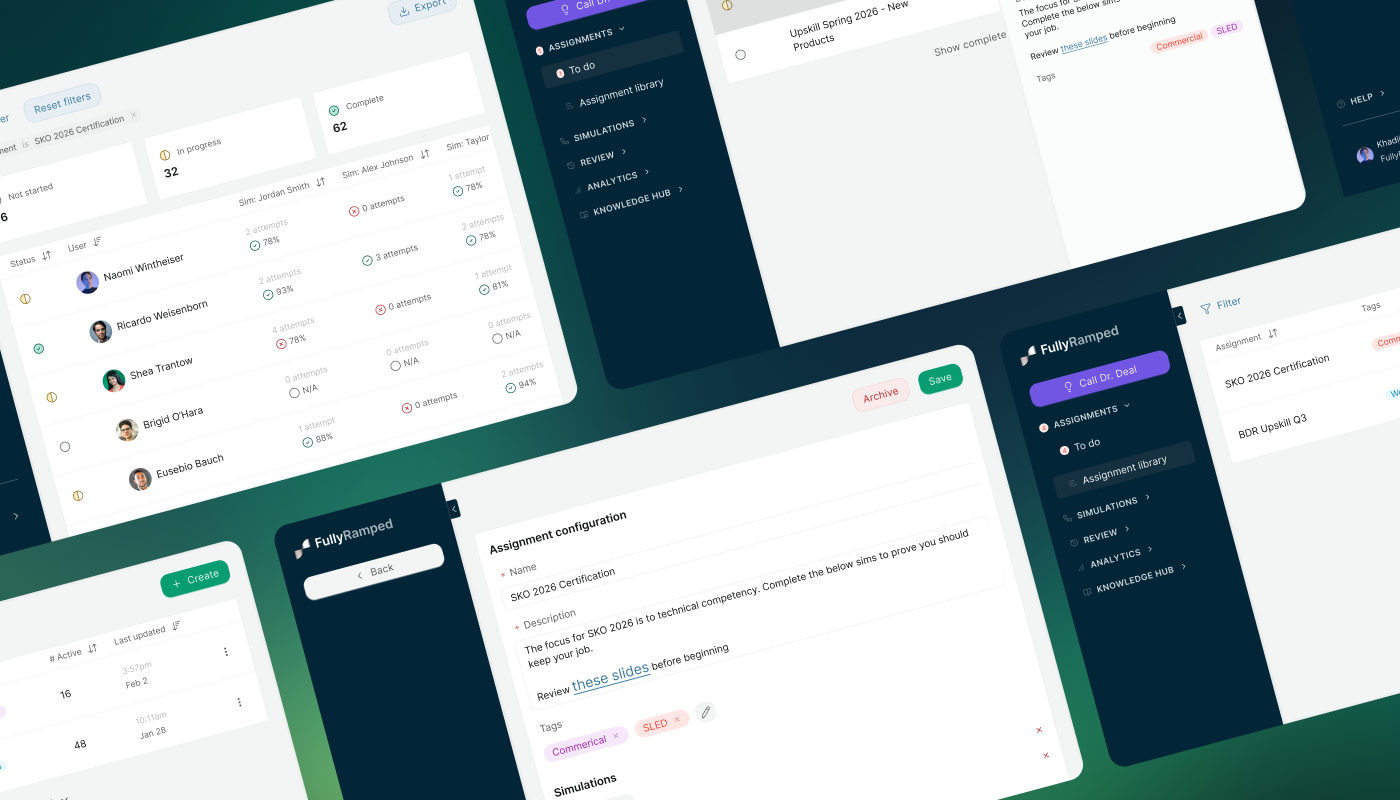
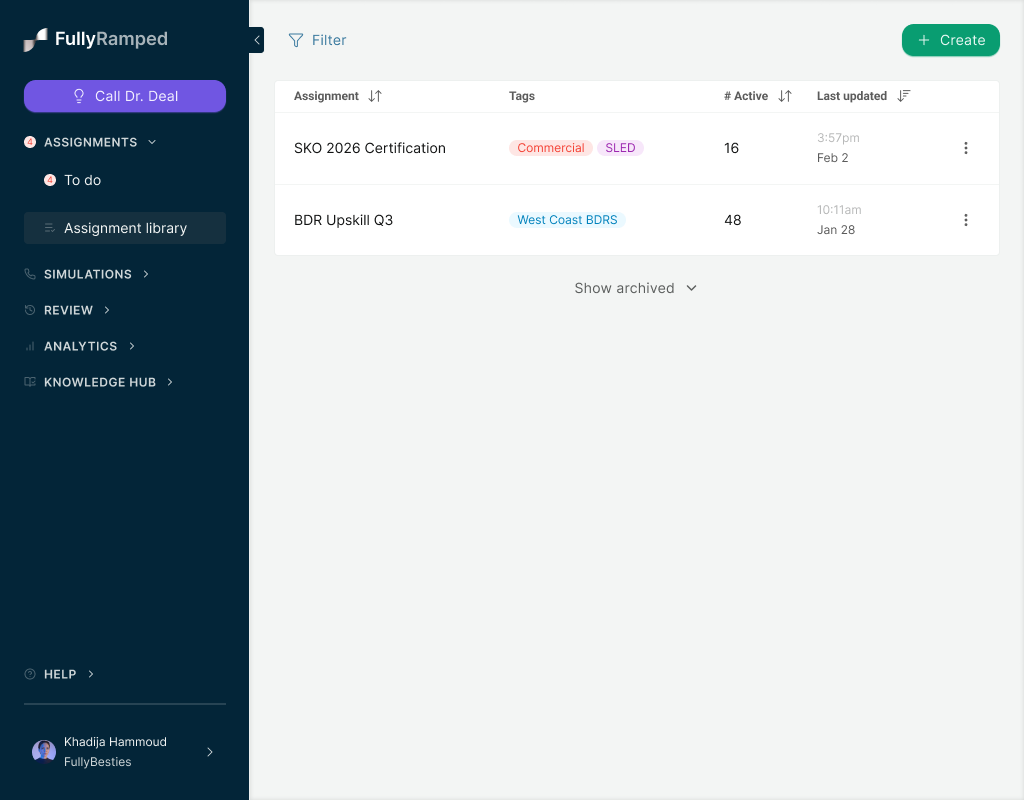
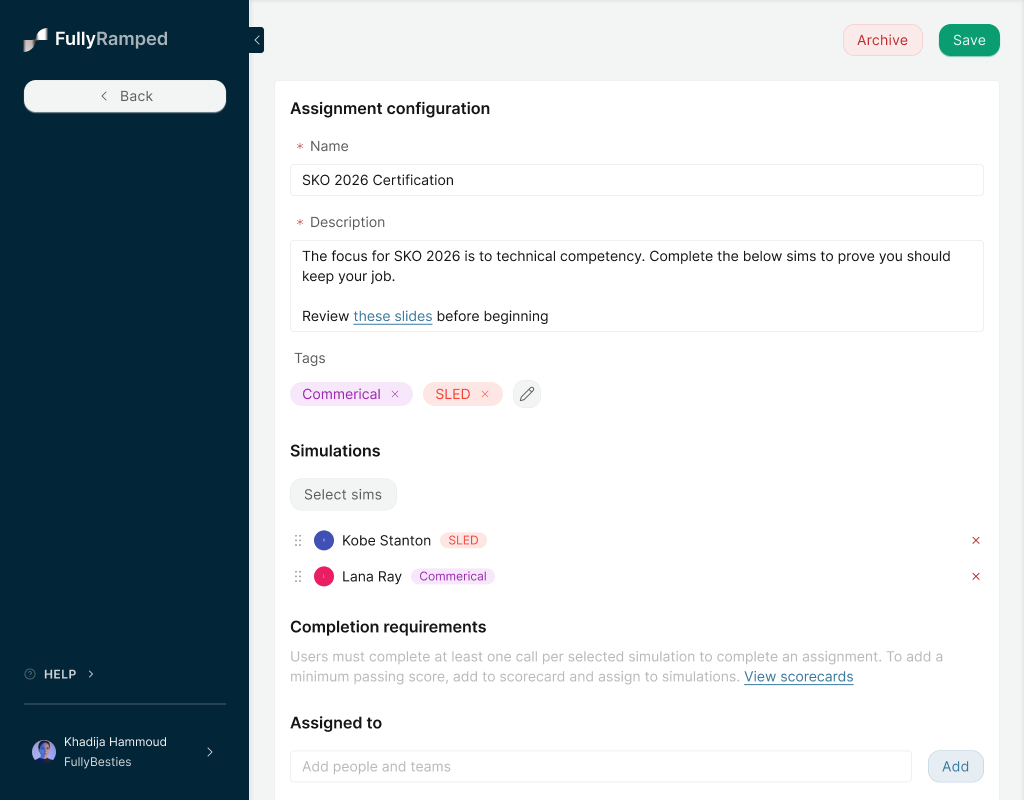
What we shipped: An assignments object. A manager picks a title, description, and a set of sims from the existing library. They assign it to individual reps or a whole team. Reps see it in a "to do" list with simple states: not started, in progress, completed. Completion criteria were deliberately simple and not configurable: if the sim has a scorecard with a minimum passing score, the rep has to hit it. If not, one completed attempt counts as done.
Notably out of scope for v1: due dates, gating sim order, optional sims, per-sim criteria, and all analytics. Zero dashboards.
I knew analytics was coming as a fast follow. I also knew more configurable completion criteria were coming eventually. But I didn't know which configuration options mattered most, and shipping the wrong ones would have been worse than shipping none. So we shipped the base case and waited for the data to tell us what to build next.
First iteration of the "assignments library". You'll also note we had some major design system upgrades in the meantime!
What we learned: Two things, roughly in order of volume.
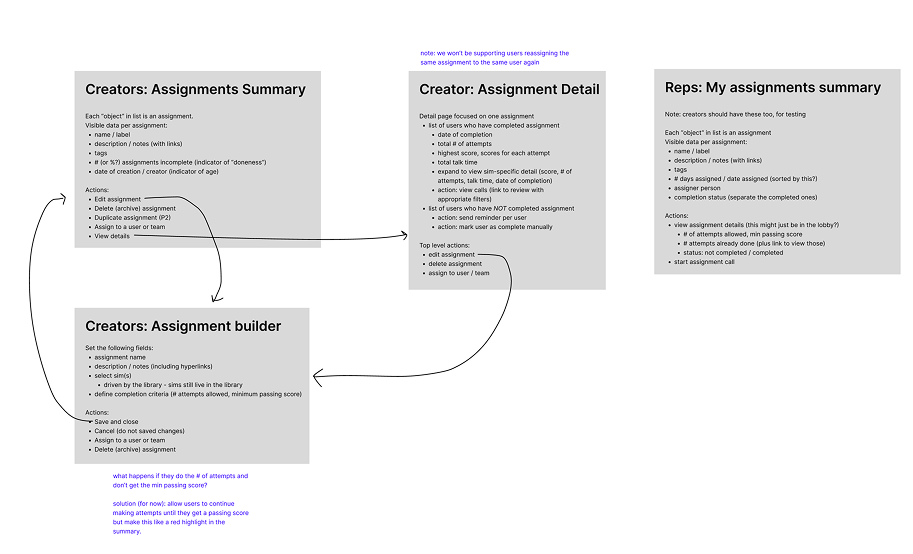
First, the completion model needed hardening. The base case (one attempt, or passing score) was the right default, but the edge cases around it were where things broke. What counts if a manager edits the assignment after a rep starts? What happens when a rep completes an assignment and the manager reassigns it? What about calls the rep ran before the assignment existed? Without clear answers, the assignments page filled up with "in progress" items that never cleared, and reps started treating the whole page as noise.
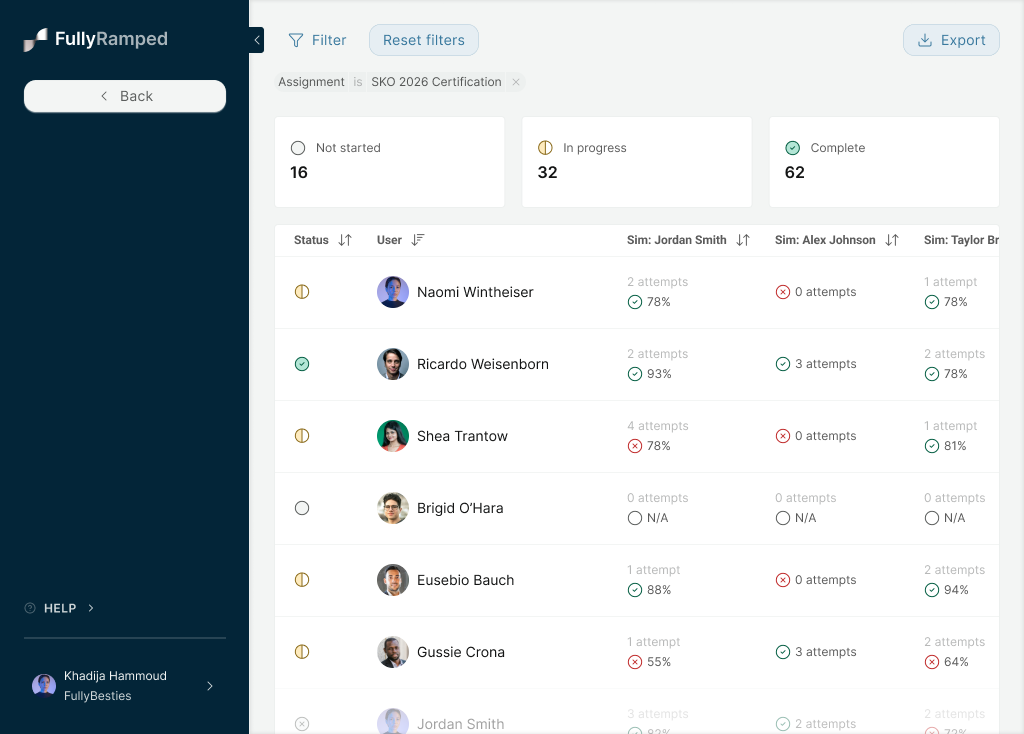
Second, analytics was louder than I expected, and more specific. Not "we want a dashboard." Four questions, from almost every customer, unprompted: what percent of my team has completed this? Who hasn't started? How many attempts is it taking to pass? What are the scores?
V2: Hardening and the analytics fast follow
What changed on completion: The base rules stayed. What got written down (for the first time in an actual PRD, because the surface had grown enough to need one) was the behavior around the edges. This is where I coined completion is a one-way street as an internal concept, because it kept coming up and deserved a name:
- Only calls initiated after an assignment is assigned count toward it. No retroactive credit
- Completion is permanent. Archiving calls or editing the assignment doesn't un-complete a rep
- Sim completions are picked up globally. If a rep runs the sim from the library instead of from the assignment, it still counts
- Reassigning a completed assignment resets it to "not started," and only new calls count
- Archiving an assignment cancels all in-flight work on it. Unarchiving doesn't re-open cancelled states
None of these rules are exciting on their own. Together they're the reason the assignments page became scannable. Reps stopped asking "is this done?" because the system answered before they could ask.
Finally wrote a "real" PRD to capture edge cases and clarify user intent (note: it was still under 3 pages and mostly bullets 🙃)
The assignment builder, adding complexity where it's needed and leaving out the rest.
Rep "todo" list with clear explanation of status and progress
What shipped as the fast follow: A dedicated analytics view, linked directly from each assignment. Completion percentage. Individual rep progress against criteria, with deep links into the actual calls. Aggregate stats like average attempts and average score. Scoped tightly to the four questions customers had already asked us, not to what a dashboard "should" have.
The reason I held analytics for v2 instead of shipping it alongside v1: you fix the source of truth, then you report on it. Building dashboards on top of data we didn't trust would have meant shipping charts that disagreed with each other.
The first iteration of the analytics page, where managers can view progress on a particular assignment
What worked about running it this way
Three things, worth naming because they're the pattern, not the project.
Every version was a real product, not a prototype. V0 shipped to customers. V1 shipped to customers. The feedback we got was from people using it in their actual workflow, not from people reacting to a mock. That's the only kind of feedback I trust for something this workflow-heavy.
Each version was scoped to answer one question. V0: do managers want to surface sims at all? V1: is "assign a set of sims" enough structure? V2: does explicit completion fix the confusion? V3: what do managers need to see once completion is trustworthy? When you stack the questions in order, each answer makes the next version obvious. When you try to answer all of them at once, you build an LMS.
Documentation caught up with complexity, not the other way around. V0 was a few bullets in a Linear ticket. V1 was a short ticket plus a Figma file. V2 is the first time I wrote an actual PRD for assignments, because the edge case logic was load-bearing enough that other people on the team needed to reason about it without me in the room. Writing a formal PRD for v0 would have been theater. Writing one for v2 was overdue.
Next
The open questions I'm still working through with the team:
- Due dates, finally. We've hit the bar where the absence of them is a real pain point rather than a nice-to-have
- Per-sim completion criteria (e.g. "three attempts on this sim, one attempt on the others")
- Sim order gating, which some customers want and others explicitly don't
- How assignments relate to the existing quiz feature, which is starting to look duplicative
If you're a founder trying to figure out what to build next and you're staring at a feature request that could be one week of work or six, I'm probably worth talking to - get in touch.